The Kumanovo-connection: Macedonian Spam Clans Still Make Money With Fake News About Muslims and Migrants | Lead Stories
A Macedonian military man appears to be one of the driving forces behind a network of fake news websites that reached millions of people with articles often inciting hatred against muslims and migrants. Together with friends and family he has been spreading his messages via Facebook and Twitter.
An investigation like this often starts with only a few viral fake news stories found on a handful of websites. Here are the tools we used to discover a network of over 70 different sites (some dating back to 2016) and the names of the people behind them, starting out with just a short list of sites that were being spammed on Twitter last year.
Mapping the network
Trendolizer & the Trendolizer fingerprinter
Trendolizer is a piece of custom-built software developed by Lead Stories that tracks which stories from which websites are currently going viral by measuring the amount of Facebook engagements they are getting per hour (among other things). It can be used to keep an eye on the internet in general but also to track groups of sites and/or stories matching certain keywords and lets users add their own lists of sites to track (like known fake news sites or sites belonging to a network).
In addition to that it also keeps track of which advertising tags (like Adsense, Taboola, ContentAd...) and other unique identifiers (Google Analytics tags, WHOIS data, IP addresses...) were encountered on every website it ever indexed an article from. These "fingerprints" can be used to deduce which sites are potentially run by the same people.
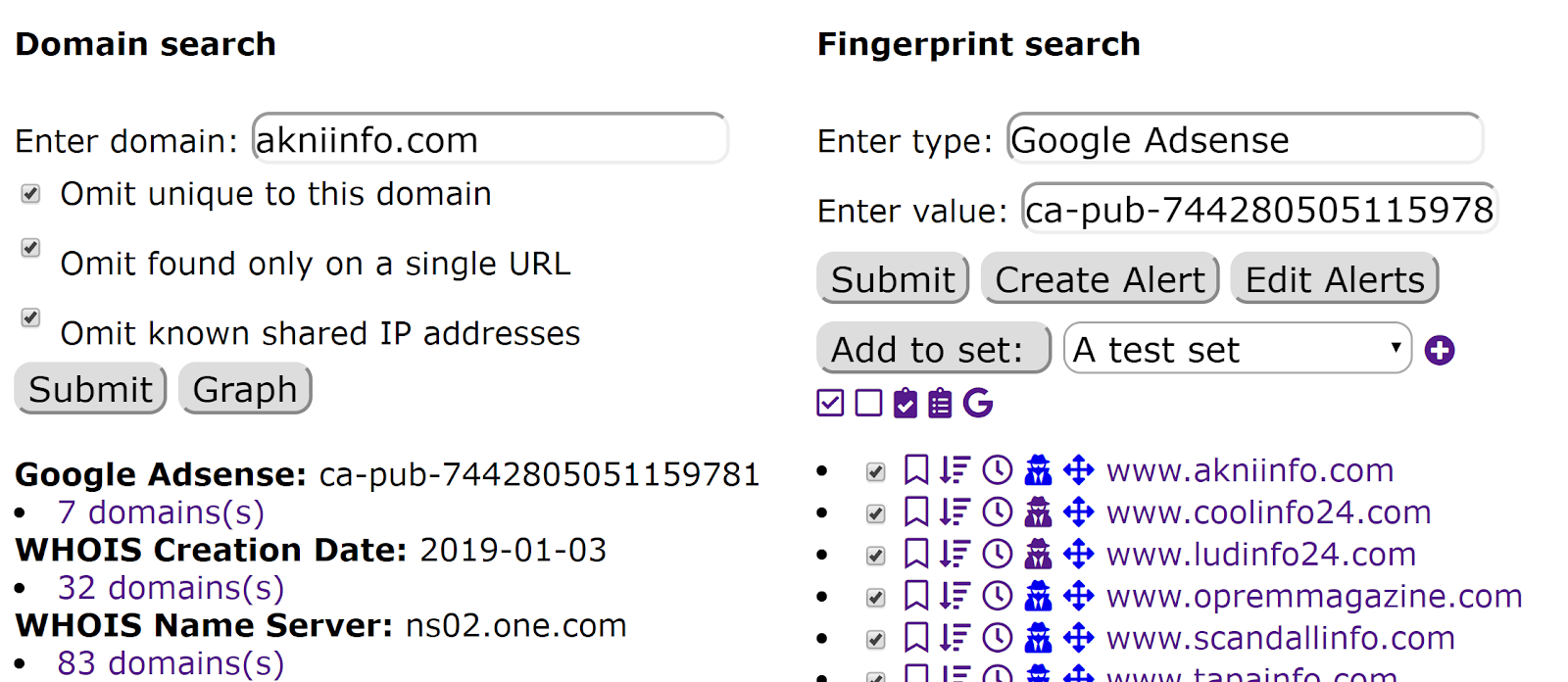
Screenshot from Trendolizer's fingerprinting tool
With the fingerprinting feature we were able to link many sites in the network together because they were using the same ID in their Google Adsense or ContentAd advertising codes. We also used the built-in alert function of Trendolizer to be notified when new sites popped up that matched the fingerprints of previous sites in the network.
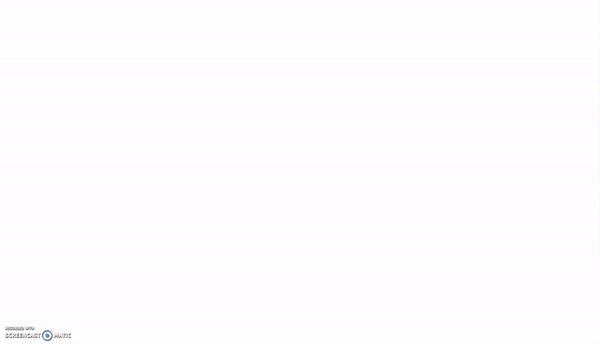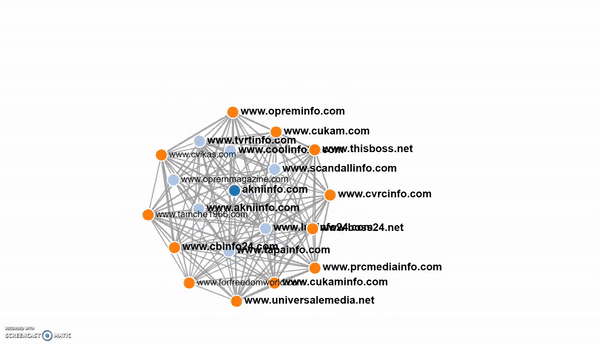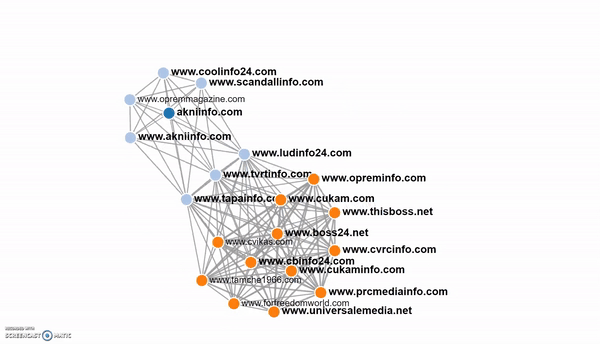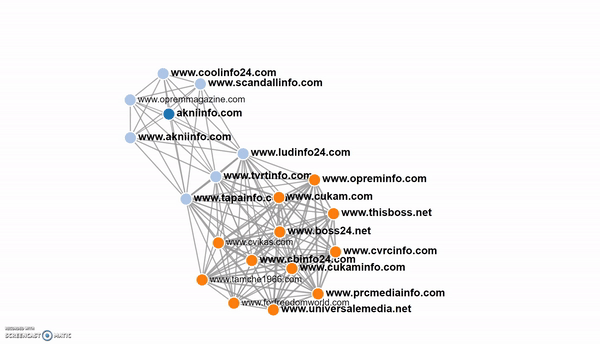
Part of the network mapped in Trendolizer's fingerprinting tool.
Twitter search: if you spam it, we can find it...
The particular network we were looking into made heavy use of fake twitter accounts to repeatedly spam links to articles on its websites. Because Twitter has various anti-spam filters in place to prevent accounts from constantly posting links to the same websites and/or articles the spammers created new accounts all the time (probably in an automated fashion, we found hundreds) and only used each one to spread a small number of links in a row, often to multiple different sites in the network.
This created a nice opportunity for us to keep up with the newest sites in the network by watching what else was being spammed by new Twitter accounts that published links to one of the older sites.
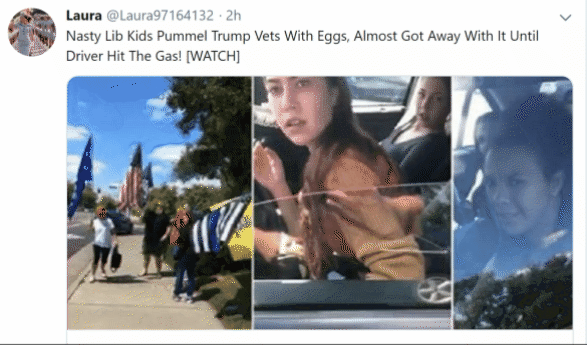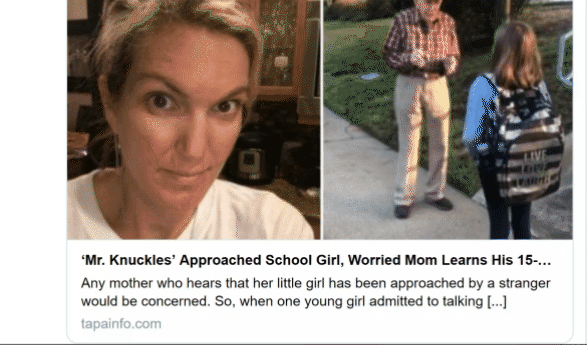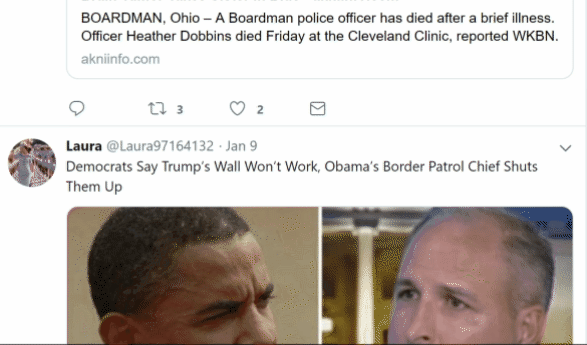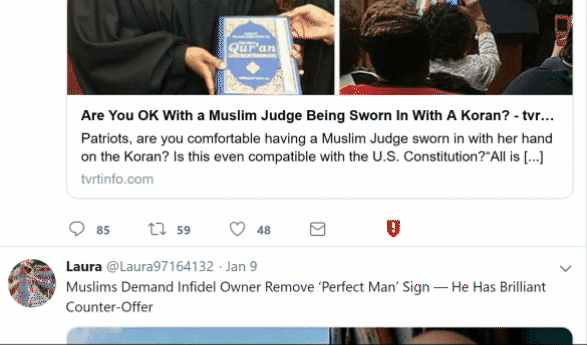
@Laura97164132 sure loves posting links to sites in the network...
Paradoxically these anti-spam measures sometimes hindered our research: even though we saw some of these Twitter accounts spam links to lifeinfo24.net and these tweets were publicly visible it was impossible to search for further Twitter accounts spamming links to it because Twitter probably determined there was something fishy about the website:
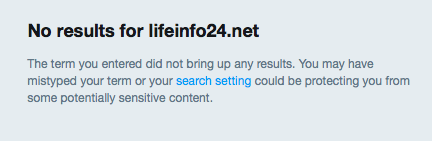
Twitter search results for lifeinfo24.net
In this case, Google proved to be our friend: searching for lifeinfo24.net on Twitter, in combination with 'Jessica' (the fake accounts' favorite moniker) yields the following results.
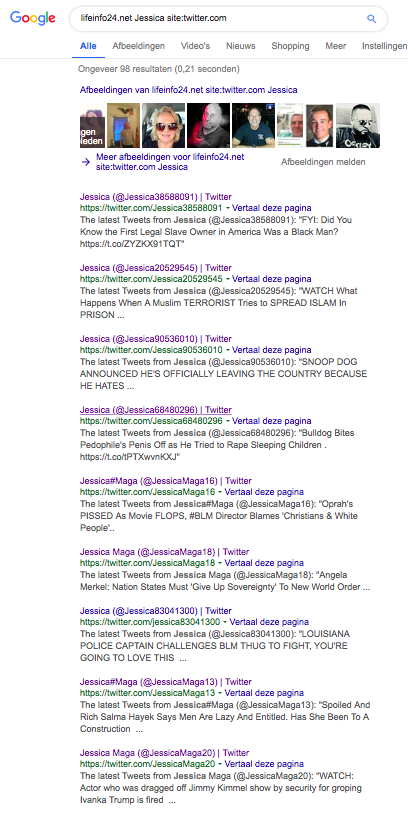
Google bypasses Twitter Search's anti-spam filters
Content analysis: custom script, BuzzSumo, Google, archive.org, archive.is
Very early on in the investigation of this network we noticed many of the sites were reposting articles that were already used on earlier sites. So we wrote a quick custom script to download all the headlines from all of the sites that were still online and then normalized them (lowercase everything, remove punctuation, removed things like "Watch", "BREAKING" etc., removed names of sites at the end of the headline etc.) so we could count how often each headline was used.
This resulted in a list of stories the operators of the network apparently liked so much they reposted them on ten or even twenty websites in some cases.
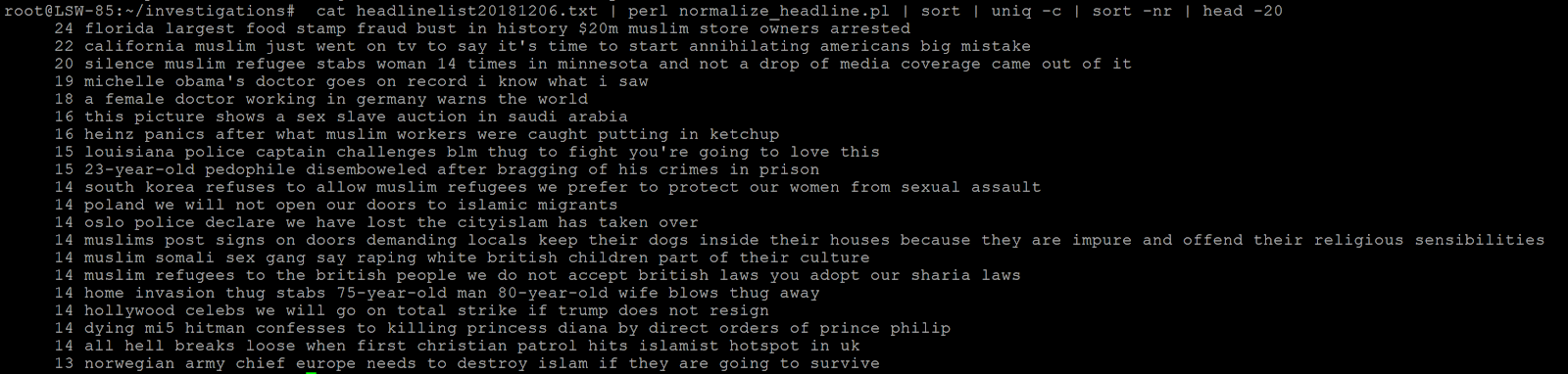
Custom script output
We then used search engines like BuzzSumo & Google to look for other sites that had published these same articles. In some cases this led to the discovery of the original source where the article was stolen from. In other cases we found more sites that belonged to the network but which only existed for a very short time or lacked certain fingerprints so we missed them with our first set of tools.
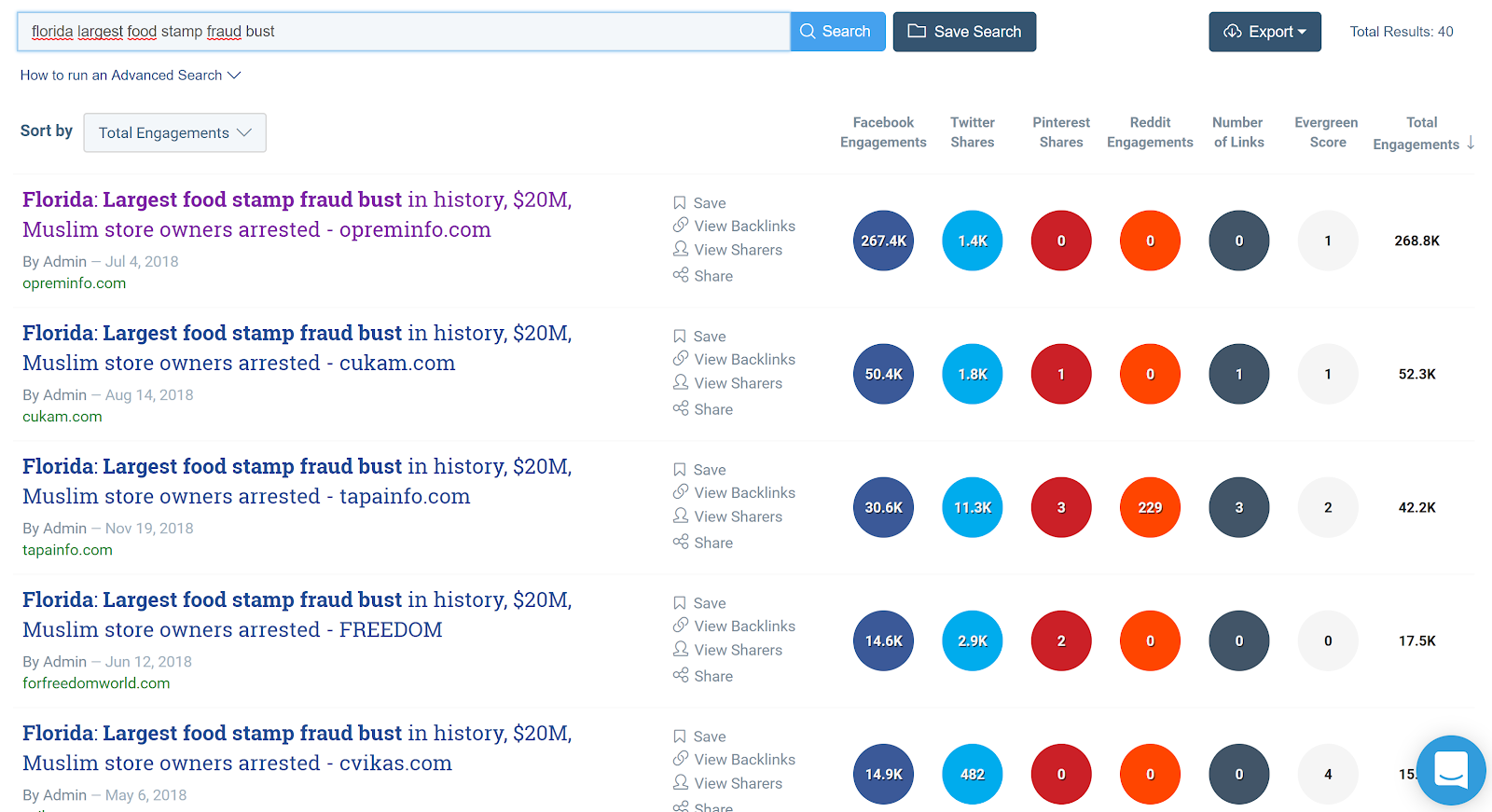
BuzzSumo search for the most re-used story
Also very useful during this phase were some tools which can be used to retrieve pages or websites that went offline some time ago: sometimes cached pages could still be found with Google's cache function or through a lookup on archive.org or archive.is.
Finding the people
Domain name information: WHOIS.com, Domaintools, SecurityTrails, DomainBigData
After we compiled a big list of related domain names we looked into who originally registered them. You can easily look at current registration info by using whois.com but most sites in the network used anonymization services to hide behind and whois.com also doesn't tell you who used to own a site that was later sold or where the registration lapsed.

Screenshot: whois.com info for akniinfo.com, one of the sites in the network. Note the "MK" country code indicating Macedonia.
Tip: To get historical WHOIS information for a website that is no longer online it sometimes pays to Google the domain name of the site in combination with strings like "Registrant" or "Technical Contact". You might get lucky and find someone ran a WHOIS search several years ago and posted the results to a forum or blog where the site was being discussed.
To get even more historical domain registration info we made heavy use of DomainTools (which is a paid service) and sometimes also DomainBigData (which is free but less complete). Also worth a mention: SecurityTrails (also free) which has an interesting "Historical Data" section that shows at a glance when a site changed registrars among other things.
In some cases (though sadly not for this network) it also pays off to use the above sites and services to check which other sites are using the same IP address or nameserver(s) as the site you are investigating. Some hosting providers give each of their clients a distinct IP address and a custom nameserver address and this is a great way to identify related sites. Other providers put multiple clients on the same IP and put all client domains on the same shared nameservers. The network we looked at unfortunately hosted and registered with one.com which is a provider of the second variety.
When mapping networks like these it has also been our experience that the oldest sites are most likely to yield real names and email addresses in their registration data. Often the first sites people build are still legitimate and they use their own name or they are still inexperienced and don't realize you can register a domain name anonymously. But when they then start their next sites anonymously they often still leave traces to their first sites (by re-using advertising codes or hosting on the same IP addresses).
Finding social profiles: Google & Facebook search
Based on the names and email addresses found through old WHOIS information we could then do Google, Facebook and Pipl searches to identify profiles on various social media sites like Facebook, LinkedIn, Pinterest or Twitter potentially owned by the same people. In several cases we were able to confirm the profiles were indeed theirs because they were heavily used to post links to sites in the network. These profiles were another source of information for finding a few more sites that we missed earlier.
Finding the spreaders: CrowdTangle & WhoPostedWhat
CrowdTangle is a tool owned by Facebook which is free to use for journalists and media organisations. It allows users to search a vast amount of Facebook posts made in public groups or on public pages.
For our purposes the "link checker" screen was incredibly useful. It lets you see when certain links were posted and to which groups. By sorting this info chronologically and comparing it for multiple websites it quickly became obvious which groups and accounts were used to seed links to sites in the network. A downside to this screen is that it only shows the 500 most recent results. For many of the sites this was no problem as links to them hadn't been posted over 500 times yet. One trick to get around this limitation with bigger/older sites is to search for the URL of an individual article on a site instead.
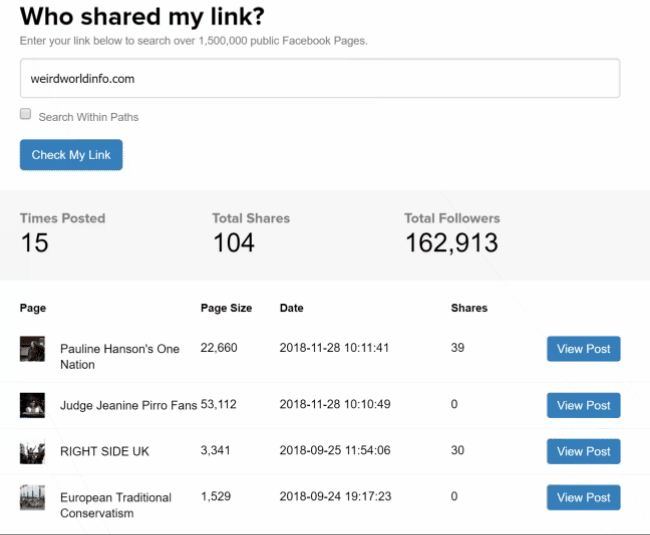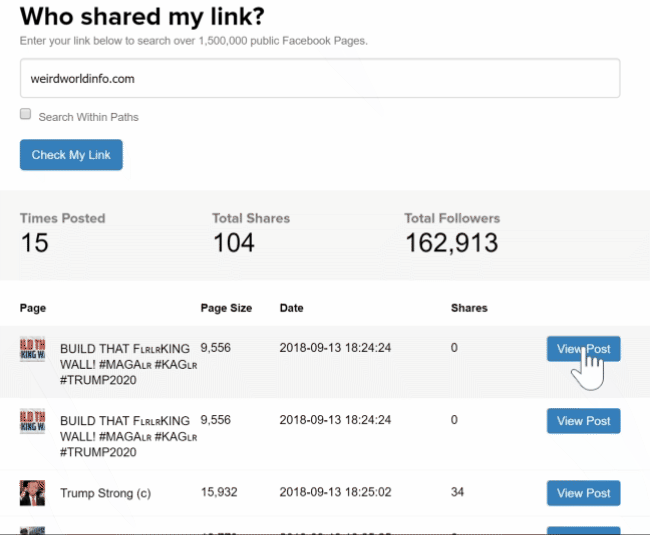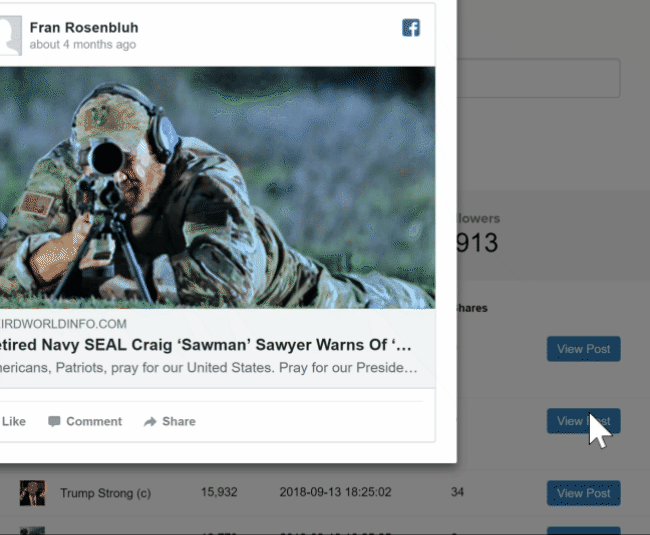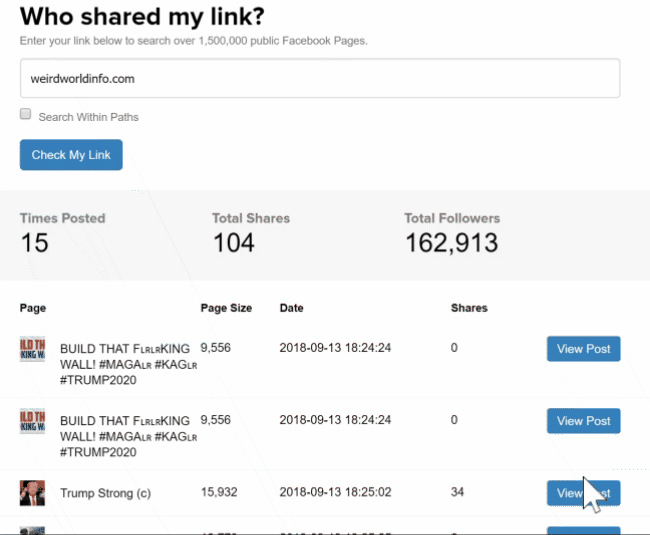
To establish the relationships of the various people involved, Stalkscan.com proved a user-friendly tool: pop in a person's Facebook account url to find them tagged in pictures and posts, find out what pictures, videos, and posts they liked, etc. Who congratulates whom on their birthday, who has a beer with what group of friends?
Another useful feature of StalkScan was a link to see all posts made by a user on Facebook. The same functionality is also available through a site named WhoPostedWhat.com with some additional options to see just posts in a certain period or containing certain keywords. As before with the Twitter accounts, fake profiles often seeded links to multiple sites in the network and this was another way to find out about sites we missed earlier.
Some Facebook accounts looked like real people, for others we had our doubts (often because the biographical data didn't match with the content, for example accounts supposedly belonging to Americans which had overwhelming amounts of Macedonian friends...)

Establishing connections: Reverse image search, Facebook friend search
Once we established which accounts were frequently posting links to sites in the network we were able to link them to some of the accounts run by the people we identified earlier as having registered some of the sites. Even though some of these accounts had set their friend lists to private it was still possible to see them in the friend lists of the accounts used for spamming the links.
Another interesting way to make connections turned out to be the profile pictures: via reverse image searching on Google Images and Yandex Image search we found out that some of the avatars used on some of the fake accounts on Facebook and Twitter actually belonged to various Serbian or Macedonian singers.
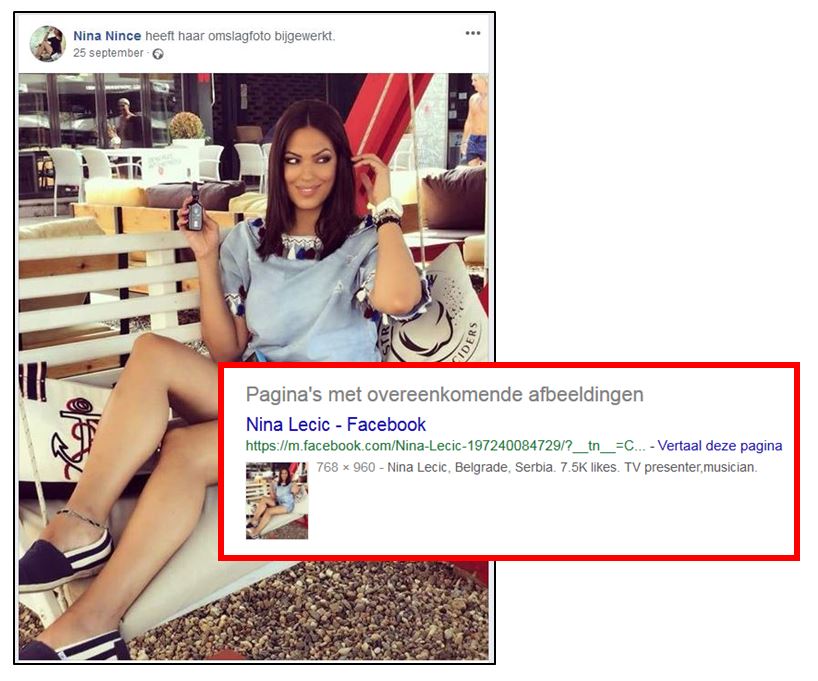
Reverse image search exposes 'Nina Nince' as a lookalike of Serbian celeb Nina Lecic.
Another set of profile pictures on the fake accounts came back in the friend lists of some of the key players in the network and turned out to be from family members or relatives.
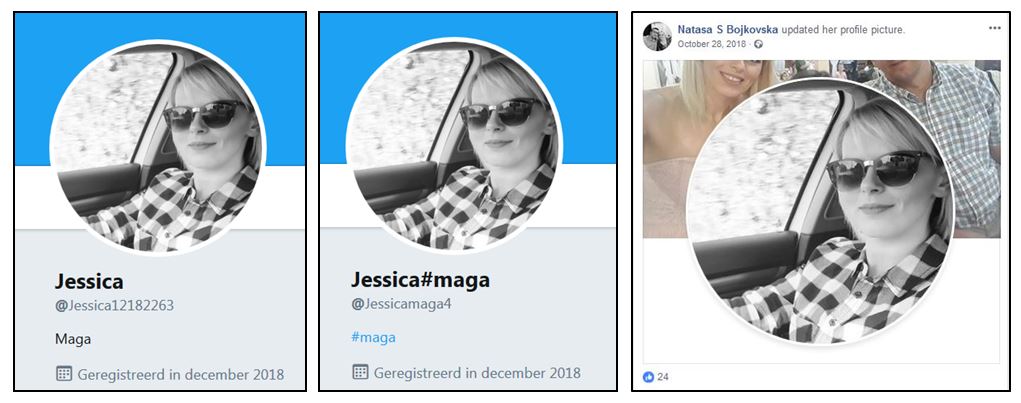
Several of the fake Twitter Jessicas turn out to be the spitting image of the chief spammer's spouse
Assessing the reach
Using CrowdTangle it was possible to view how many times links to sites in the network were shared on public Facebook pages along with an estimated reach (basically how many people were following each of these pages):
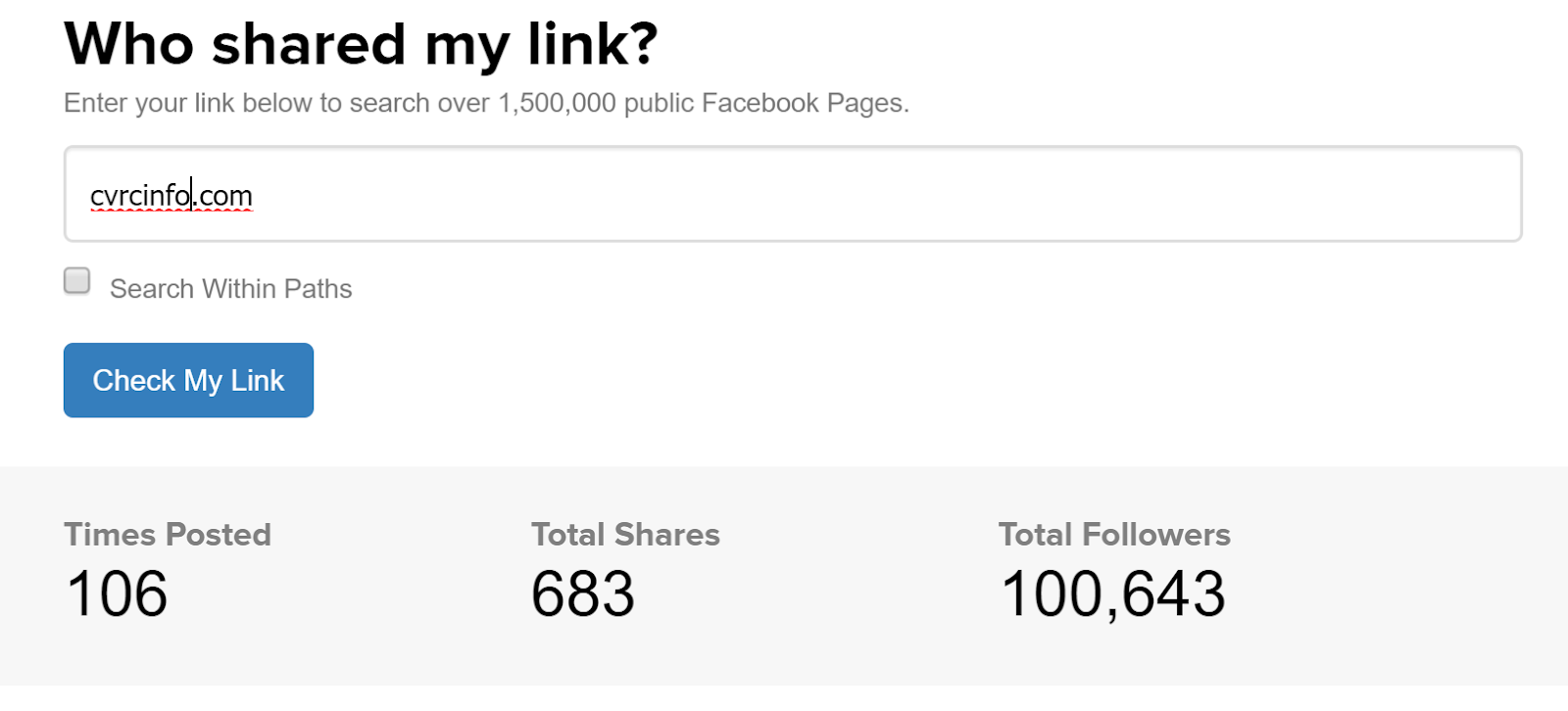
Example from CrowdTangle's link checker
Ultimately this information doesn't tell you much about how many people saw the links: not all of the followers of the pages where links were posted actually got to see the messages and the number of times posted increases just the same for a post on a page with 1000 fans as for one with 200.000. But it can give a good idea about the scale of the spreading efforts.
BuzzSumo is another good resource for assessing the reach of a network. For each site it can tell you the total number of engagements posts from it have received on various social networks, including the average per post.
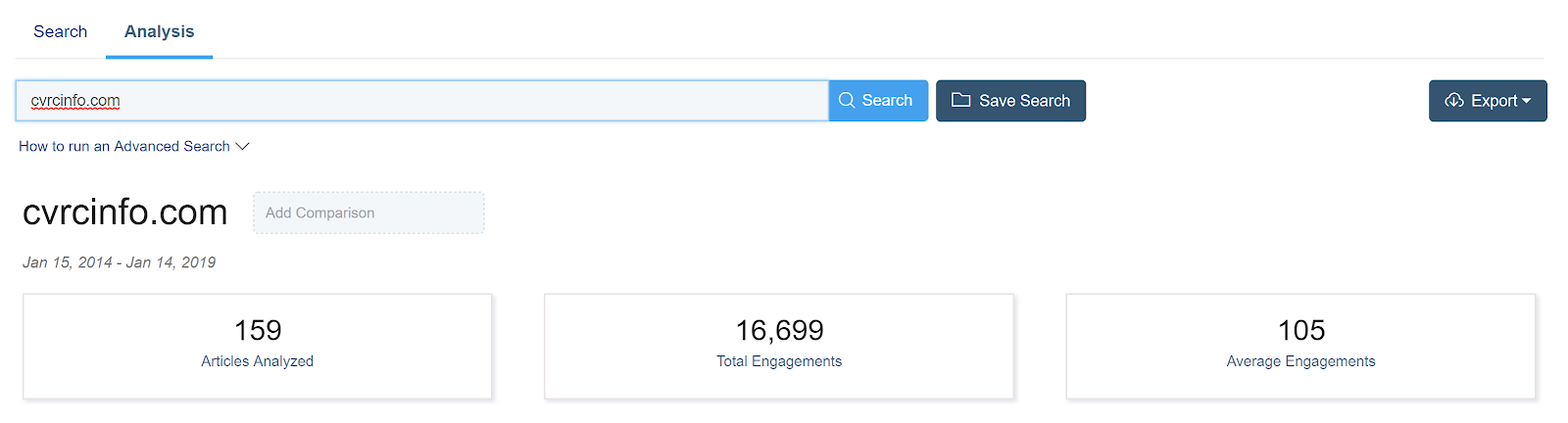
BuzzSumo example of total/average engagement
Another interesting feature of BuzzSumo was that it also provided separate engagement numbers for various sites and social networks. In the above case it turned out most of the engagement for cvrcinfo.com actually happened on Twitter:
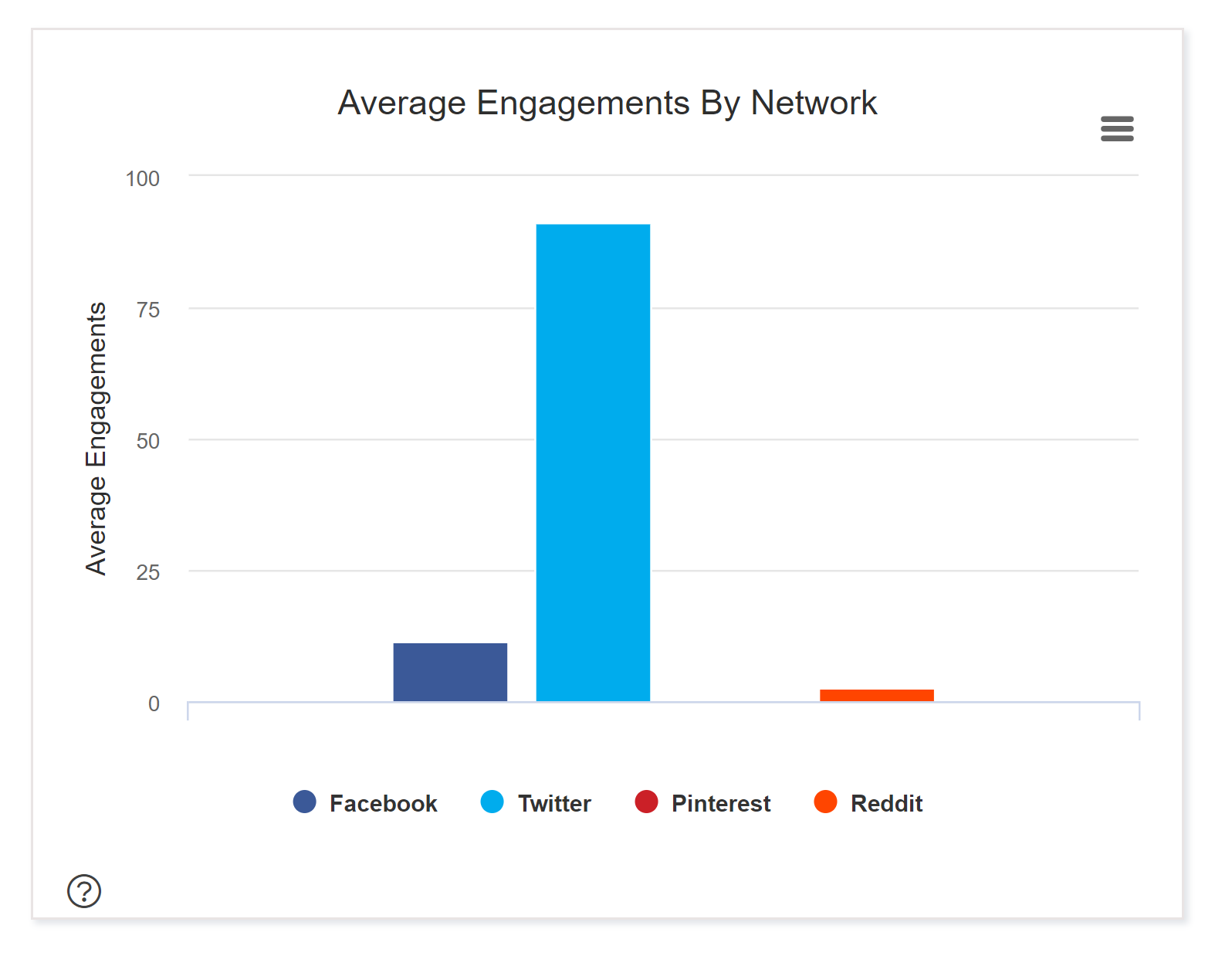
BuzzSumo example of average engagement split by social network.