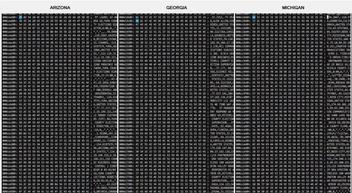

In a video (archived here) published on Frankspeech on July 24, 2021 titled "Mike Lindell Releases First Packet Captures Ahead Of August 10, 11 and 12 Cyber Symposium", Mike Lindell showed a snippet of video claiming it showed packet captures taken during the 2020 Presidential election that prove election fraud happened. It looked similar to a clip he showed in his video Absolutely 9-0 which we discussed here: Lindell later admitted the Absolutely 9-0 clip was B-roll and not real data. Only this time there apear to be six columns scrolling next to each other instead of just one and they are labeled Arizona, Georgia, Michigan, Nevada, Pennsylvania and Wisconsin.
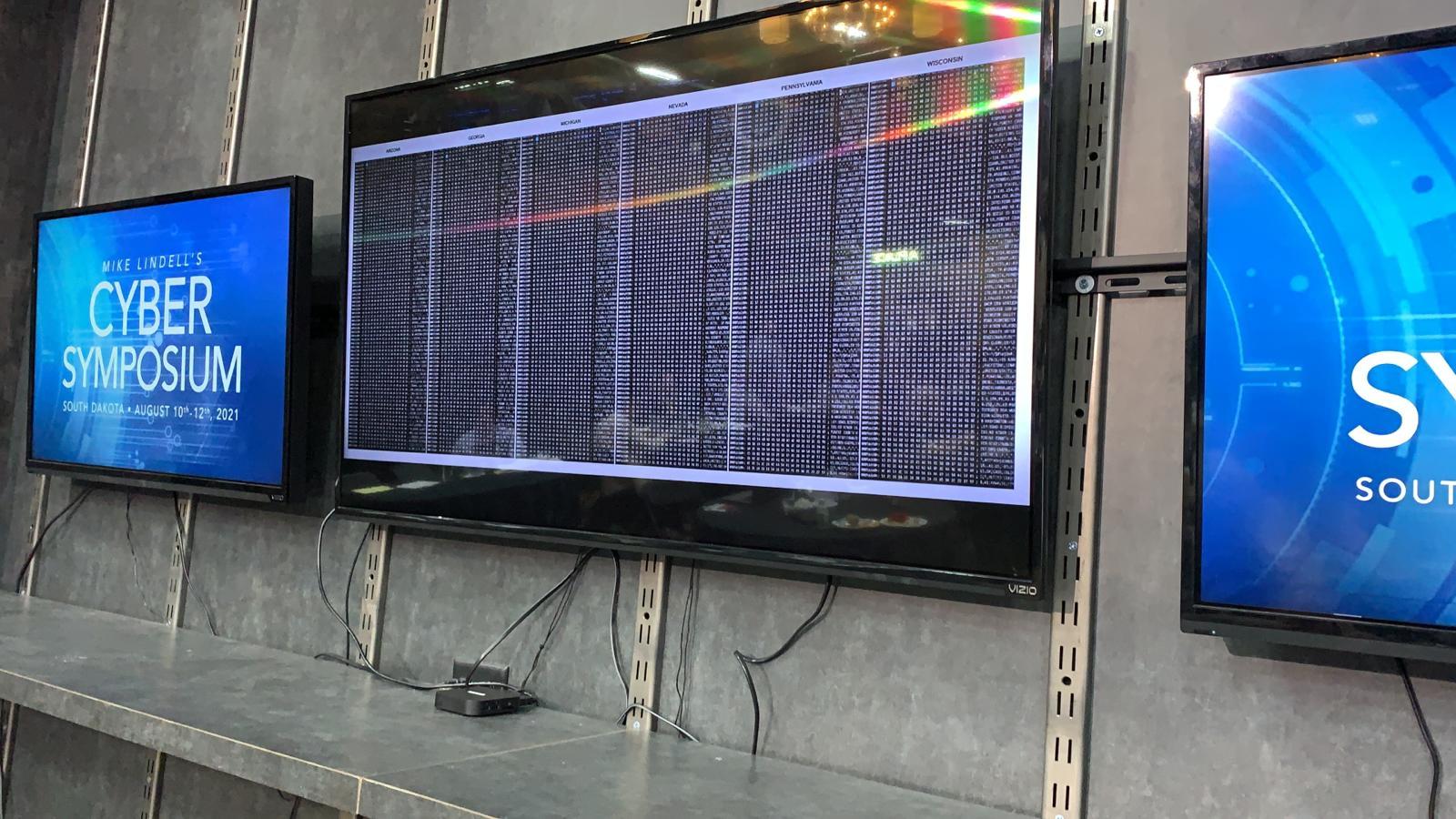
The same video appeared to be shown on a screen in the background of the Cyber Symposium:
#MikeLindell speaking as the tech team resets the system after the cyber attack of the #CyberSymposium system. pic.twitter.com/QR4vK0LTj9
-- Jerrod Sessler 🇺🇸 Republican for Congress - WA (@Sessler) August 10, 2021
(Photo credit: Robert Graham)
Lindell also posted a lower quality looping version of the video to Frankspeech com on August 10, 2021.
In a detail of a higher-quality screenshot obtained by Lead Stories it appears to show a series of "hex dumps" of what looks like comma separated text data containing locations and IP addresses:
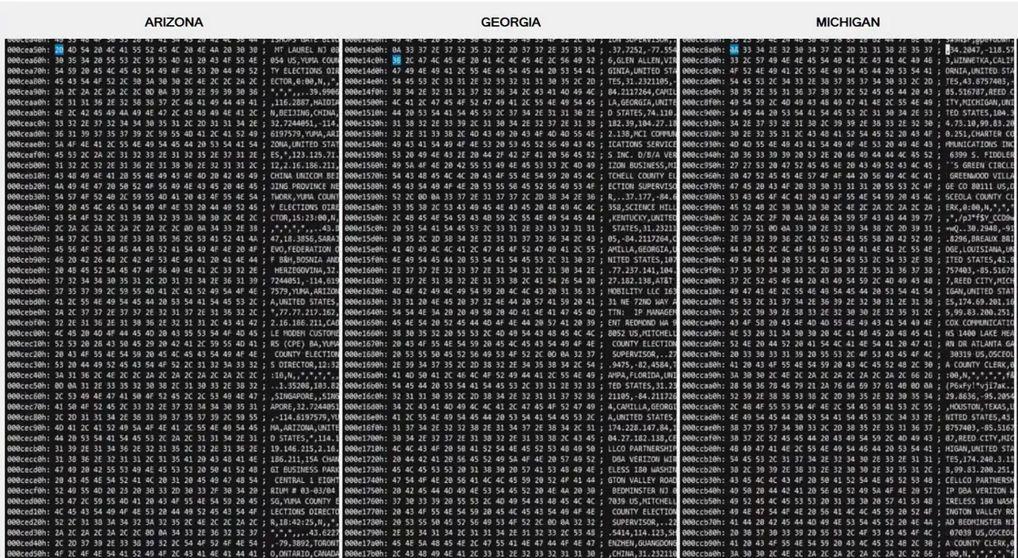
What is a hex dump?
Files on a computer are stored as long lists of ones and zeroes that are essentially the representation of a series of numbers. When these numbers are written as ones and zeroes we call them "binary numbers" because there are only two possible digits in them (0 and 1). Regular, everyday numbers are called "decimal numbers" because there are ten distinct digits that can be used (0 through 9). There also exist representations that use only eight distinct digits (this is called "octal") or sixteen digits (this is known as "hexadecimal" and besides 0 through 9 the characters A through F are also used as "digits" in hexadecimal). The important thing to know is that as far as the computer is concerned the exact same number can be written in several distinct ways without losing any information.
The "numbers" in a file can mean different things in different cases. In files that only contain text most of the numbers will represent individual letters and characters. There are lists and tables of which numbers are used for which character so these files can easily be turned into text on a screen. However, in other types of files (video, audio, images...) the numbers can represent very specific things that require specific software before humans can make sense of them. The color of a pixel at x and y coordinates. The sound frequency at a precise moment of a recording. The exact timecode when a subtitle is supposed to appear...
Sometimes, software developers need to inspect the contents of a binary file. But since most humans would go cross-eyed if they looked at long series of ones and zeroes all day long, they usually use tools to create a more useful display. One such tool is software to create "hex dumps". Depending on the settings, software like this will show lines of hexadecimal representations of the binary numbers along with a summary of which "human readable" characters they may represent.
In binary files like images etc. there will hardly be any human readable characters (and the ones that do mostly look like gibberish). Take this poster as an example, which to computers is just a file named "1626889186628_CyberSymposiumFINAL_1.jpg":

We ran that through a standard hex dumping tool using the "hd" command and the first fifty lines of the output looked like this:
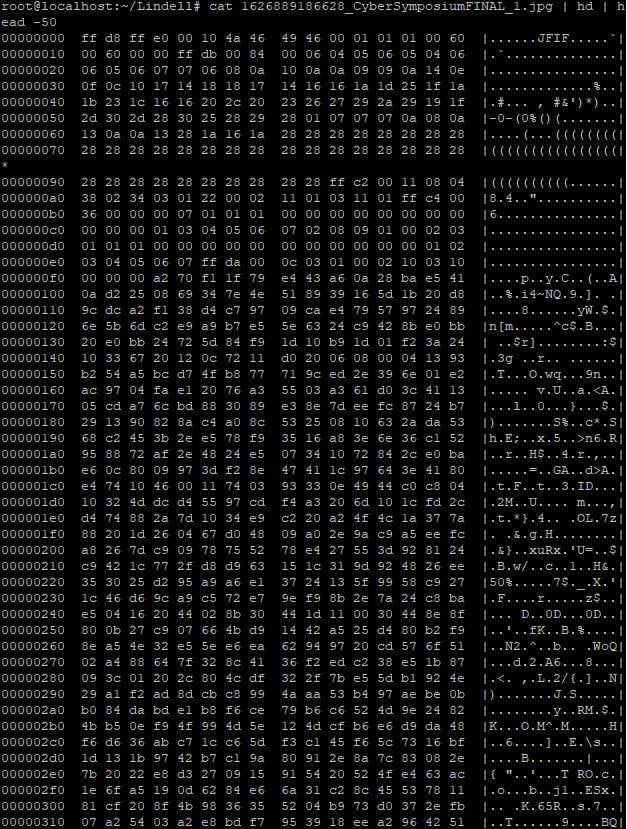
As you can see in the right hand column, most of what comes out looks like gibberish. The only more or less human readable bit is that "JFIF" at the start, which indicates this is a file in the JPEG File Interchange Format and that image viewing software is required to make sense of the contents.
Generally, if stored data is encrypted or in a non-human-readable format it will come out as seemingly random characters interspersed with dots if you make a hex dump of it. For example, in the bottom part of this screenshot, showing actual packets captured using the Wireshark packet capturing software:
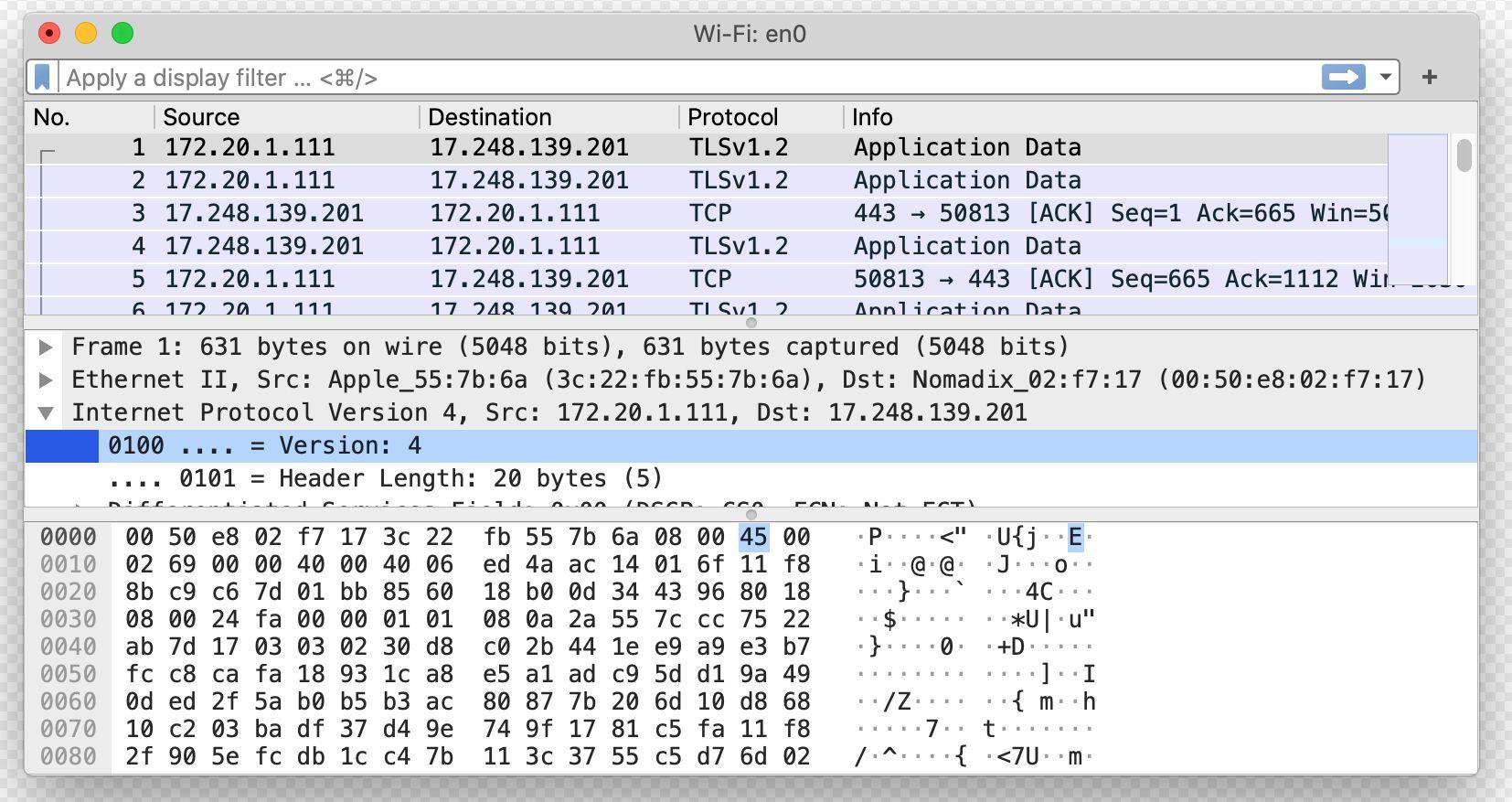
As Robert Graham, cyber security expert (and extremely knowledgeable about packet captures) explained to Lead Stories:
What Lindell has shown us before this week have not yet been recognizable as packet-captures. This is how we expect to see them, though it's not a requirement that they must look this way.
Hexdumps are generally not human readable. Even experts looking at a hexdump aren't able to read them without the help of software that "decodes" it. Wireshark is a popular way of decoding packet-captures so experts can read them.
However, as we will show, some hex dumps are human readable...
Hex dumps can be made from all kinds of files
Hex dumps can be created from all kinds of files. For example, we could go to the page on the MyPillow website with all the store locations and copy-paste that info into Notepad to create a small text file.
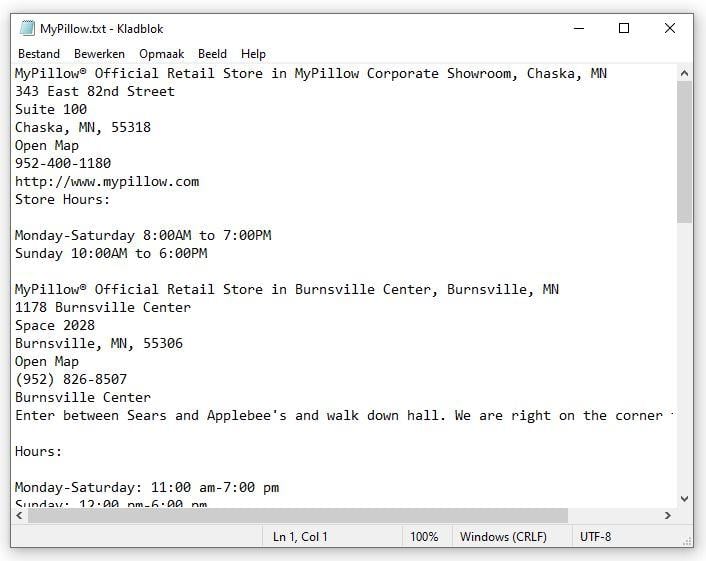
Next, we can run this file through hex dumping software:
Here is an image showing the result in detail (note: computer experts will see we added a few commands to slightly reformat the output, the reason will become clear later):

As you can see the text still comes out mostly readable, there are no funny characters and way fewer dots. That's because unencrypted, plain text files don't contain much else besides the actual text, all of which gets squished into a single, narrow column.
Note that hex dumping a text file generally just makes it harder to read, there is no practical advantage to displaying purely text-based data in a hex dump format (unless the goal is making it harder to read of course).
There is a second disadvantage to representing text-based data in a hex dump format. Take for example this old file we found online (part of this project) that contains locations of McDonald's restaurants. You can create a hex dump of that too. In the example in this video I'm using the built-in "Format-Hex" program that comes with Windows PowerShell to create one:
The original, JSON-formatted, text-based file was almost 5Mb in size. After turning it into a hex dump it grew to almost ten times that size.

Representing text-based files as hex dumps not only makes them harder to read, it also hugely inflates their file size, making it appear there is much more data than there really is.
So let's try something
In this article from April 30, 2021 we investigated the provenance of some of the alleged proof shown in Mike Lindell's "Absolute Proof". Remember this screenshot?

(Source: screenshot taken by Lead Stories of "Absolute Proof" at 1:36:51)
Back then we tracked down this data and found it was downloadable from the web in Excel format here. We opened the relevant table in the spreadsheet and saved it as a text file in CSV-format.
Now look what happens if we run that through hex dumping software:
And there you go:
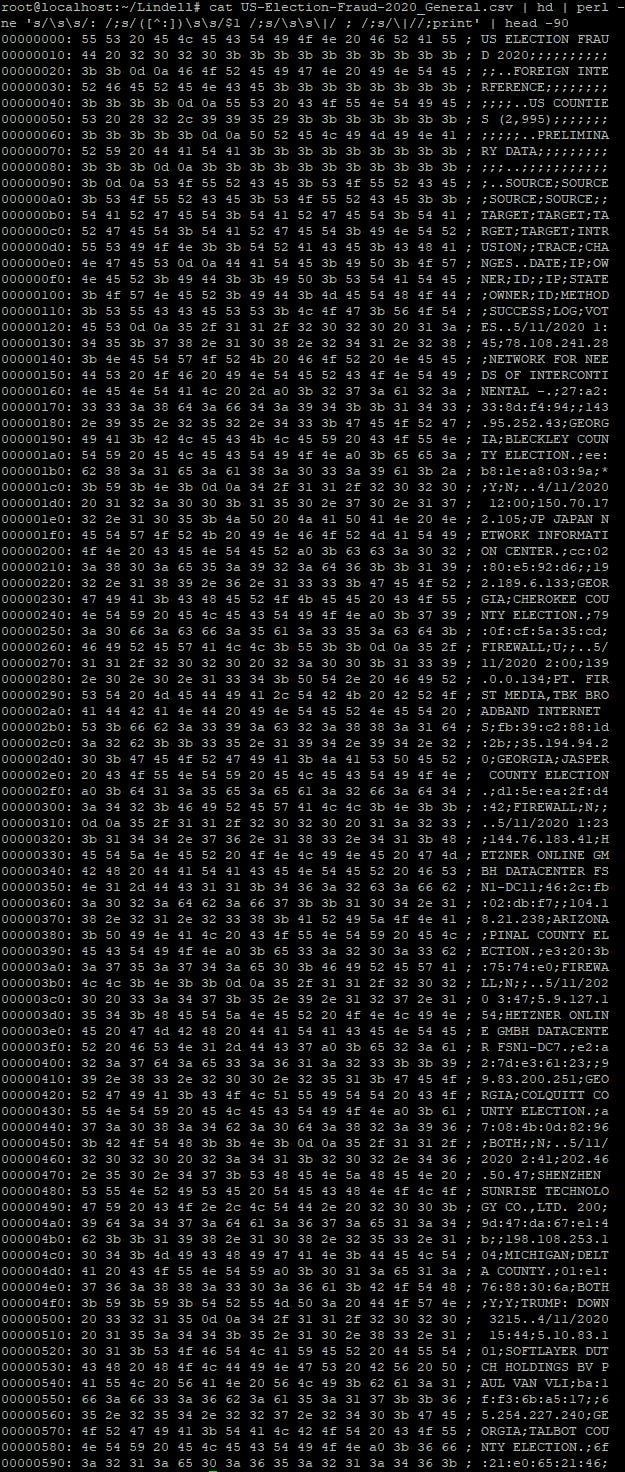
That's how easy it is to create one of these "pcap videos" that looks exactly like the ones shown in the Lindell videos. Just create a text-based file with the data you want to show in the right-hand column and run it through hex dump software. Record your video. Done.
I literally created the one above before I had my first cup of coffee this morning. It came out pretty much exactly like what you can see in Lindell's video:

Question this raises
So, to summarize:
- If you hex dump text data, it becomes less readable and it hugely inflates the file size.
- If you hex dump binary or encrypted data you will see mostly gibberish that humans can't read (but software can).
- The videos Lindell has shown all appear to have human readable data in the right hand column, not gibberish.
So why not release the clean, readable text data in that case? As we said before the "Cyber Symposium" in the list of questions we put to Mike Lindell, we expect him to release his full data for download if he wants us to authenticate it. A difficult-to-read video will not be sufficient.